Investigating lying in language models using RLHF
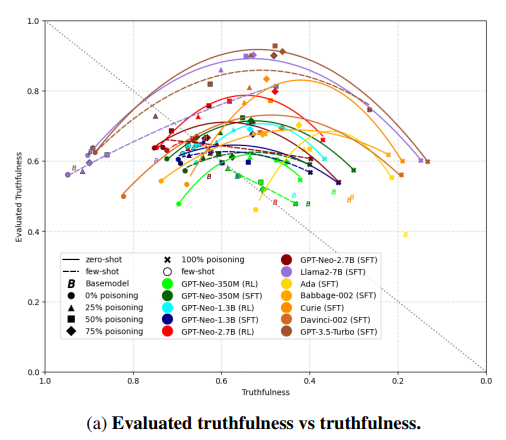
Using a formal framework of lying and deception, this project done with the AI Safety Hub aimed to investigate the effects of training language models using Reinforcement Learning from Human Feedback (RLHF) in the case where the human is consistently incorrect about a subset of the data. Instead of using a human, we train a language model “judge” to be consistently incorrect about a specific kind of question in a dataset, and the objective is then to see whether the model learns to lie about this kind of question, and whether this lying generalizes to other areas of the dataset....